上一篇簡單介紹 TensorBoard 的功能,並且測試以下功能:
這次,我們要測試其他功能:
詞嵌入(Word Embedding) 也是一個很好玩的工具,不過它屬於自然語言處理的一部份,我們之後有機會再介紹。
要顯示訓練過程中的權重(weights)、偏差(bias)分佈,非常簡單,只要在定義 tensorboard callback時加一參數即可,histogram_freq=1 表示每一個執行週期(epoch)統計1次直方圖。
tensorboard_callback = [tf.keras.callbacks.TensorBoard(log_dir='.\\logs', histogram_freq=1)]
點選【histograms】頁籤,顯示如下,越近的分佈為最後訓練的結果。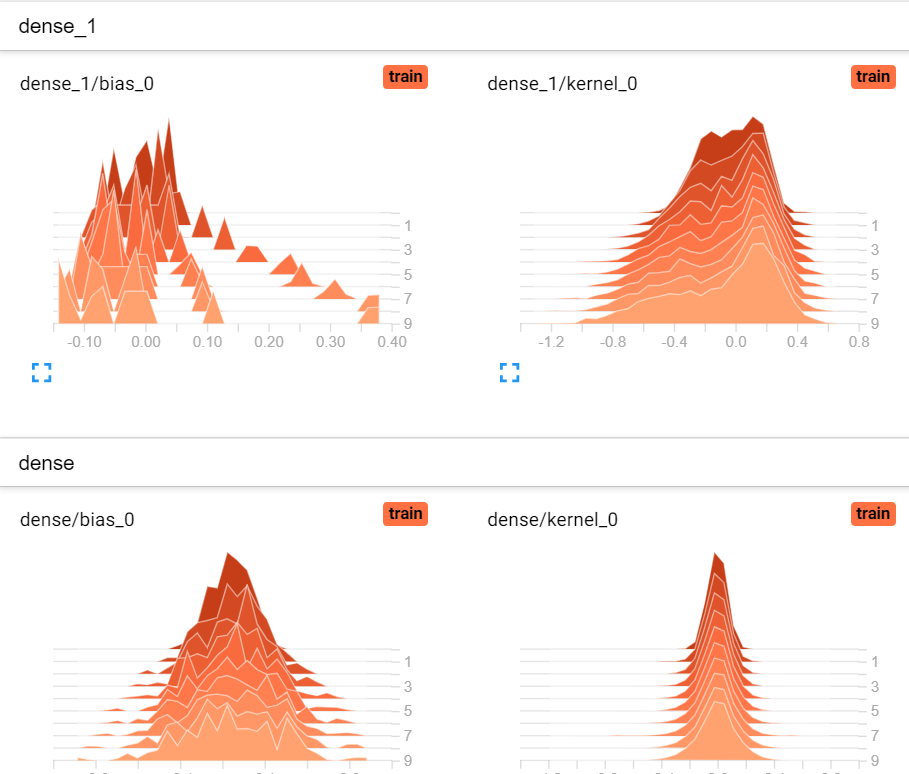
程式名稱為07_01_Callback.ipynb。
與GridSearchCV類似,設定多個參數組合,如下:
# 參數組合
from tensorboard.plugins.hparams import api as hp
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
依每一參數組合逐一執行訓練。
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
點選【hparams】頁籤,顯示如下,第6回合準確率最佳。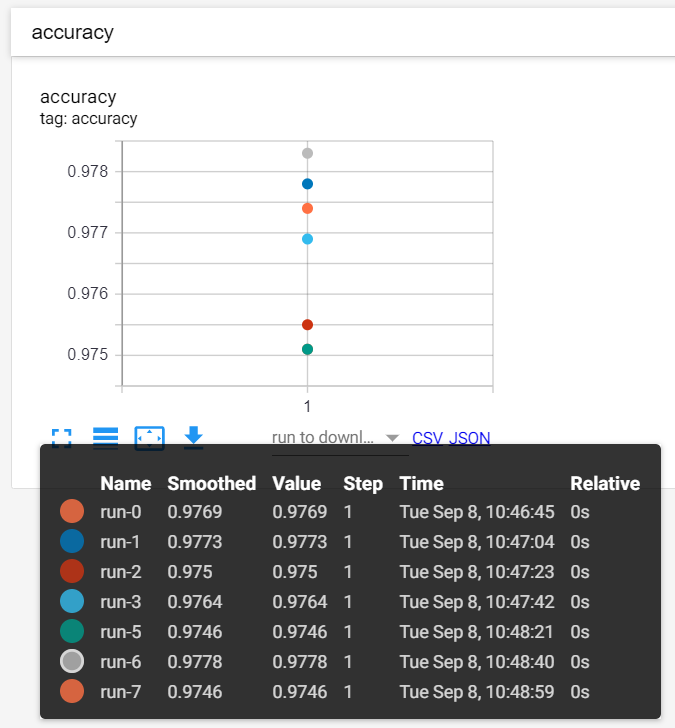
詳細資訊如下: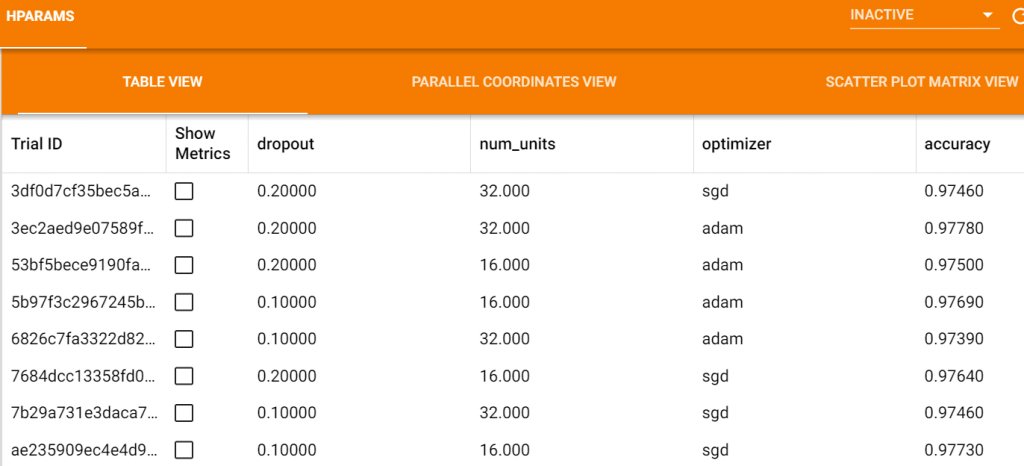
從下圖粗紅線可以找到最佳參數:
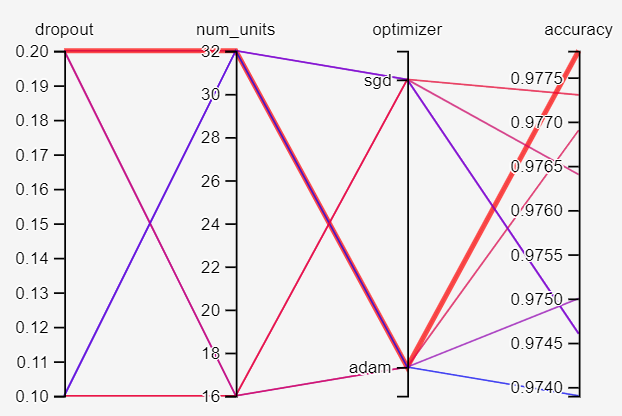
程式名稱為08_02_TensorBoard_Tuning.ipynb。
WIT 能幫助我們更了解分類(classification)與迴歸(regression)模型,它擁有非常強大的功能,包括:
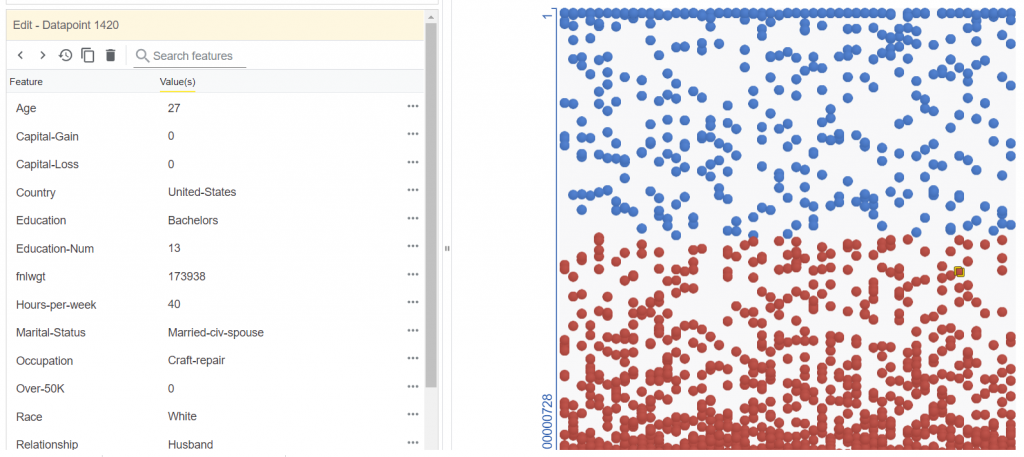
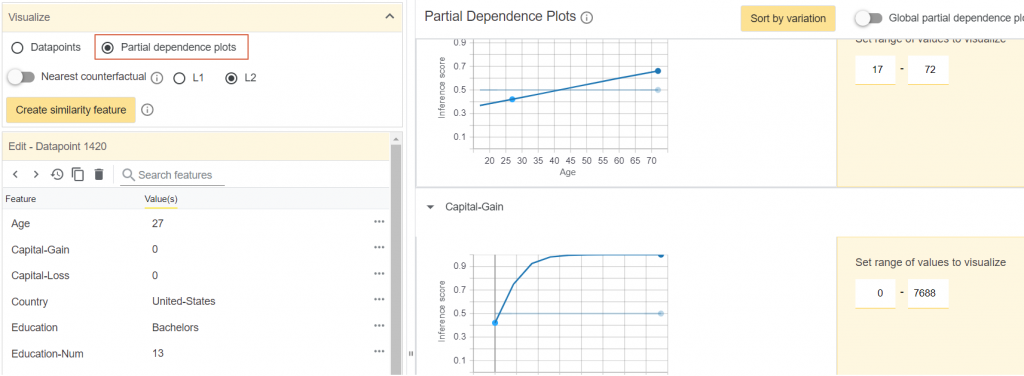

詳細操作說明可參考【A Walkthrough with UCI Census Data】,【範例】可在Colaboratoy環境執行,這是一個二分類的模型。
程式不涉及深度學習,筆者就沒仔細研究了。
TensorBoard功能愈來愈多,可以寫成一本書了,以上我們只作了很簡單的實驗,如果需要更詳細的資訊,可以參考【官網】。
本篇範例包括07_01_Callback.ipynb、08_02_TensorBoard_Tuning.ipynb、09_01_What_If_Tool_Notebook_Usage.ipynb,可自【這裡】下載。

